تكنولوجيا

كيف يتعلّم الذكاء الاصطناعي من التجربة؟ قصة التعزيز الذاتي في عقول الآلات
يتعلّم الذكاء الاصطناعي بطرق مختلفة، أبرزها التعلم بالتعزيز الذي يمنحه القدرة على اتخاذ قرارات ذكية عبر التجربة والمكافأة. ومع تطور الخوارزميات، أصبحت قادرة على استنتاج الأنماط من بيانات ناقصة

علي أبو الحسن - كاتب
أستاذ جامعي وباحث في الذكاء الاصطناعي وأمن المعلومات، أُعنى بنشر المعرفة وتبسيط مفاهيم التكنولوجيا بلغةٍ سهلة تُناسب الجميع.
أكتب لأجعل التقنية مفهومة وآمنة في حياتنا اليومية، ولأساهم في بناء وعي رقمي مسؤول.
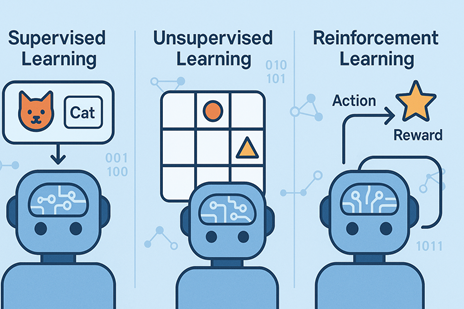
في عالم الذكاء الاصطناعي، لا يكفي أن نغمر الآلة ببحر من البيانات لتصبح ذكية. فطريقة التعلم نفسها هي التي تصنع الفارق. هناك ثلاثة أساليب رئيسية يتعلم بها الذكاء الاصطناعي، ولكل منها فلسفته الخاصة: التعلم المُراقَب (Supervised Learning)، والتعلم غير المُراقَب (Unsupervised Learning)، والتعلم بالتعزيز (Reinforcement Learning). تشترك هذه الأنماط في أنها جميعًا تحاول جعل الآلة تتخذ قرارات أفضل، لكنها تختلف جذريًا في كيفية الوصول إلى ذلك الهدف.
في التعلم المُراقَب، نتعامل مع بيانات جاهزة ومصنّفة سلفًا. كأننا نعلّم طفلًا عبر أمثلة واضحة: “هذه قطة، وهذا كلب”. النموذج يرى الصور ويقارن بين ما يتوقعه وما هو صحيح فعلًا، ثم يصحّح نفسه تدريجيًا حتى يصبح دقيقًا في التمييز. هذا النوع من التعلم هو أساس أنظمة التعرّف على الوجوه أو البريد المزعج أو التشخيص الطبي عبر الصور.
أما في التعلم غير المُراقَب، فلا توجد تسميات ولا إجابات جاهزة. هنا نترك الآلة تتأمل البيانات وحدها وتكتشف الأنماط المخفية فيها. كأننا نطلب من الطفل أن يرتّب مجموعة صور دون أن نقول له ما الذي يجمعها. بهذه الطريقة، يستطيع الذكاء الاصطناعي مثلًا اكتشاف مجموعات العملاء المتشابهين في متجر إلكتروني أو تحليل سلوك المستخدمين على مواقع التواصل الاجتماعي دون أي تدخل بشري مباشر.
لكن التعلم بالتعزيز (Reinforcement Learning) هو القصة الأكثر قربًا من التجربة الإنسانية. في هذا النوع، لا نزوّد الآلة بإجابات جاهزة ولا نطلب منها مجرد اكتشاف الأنماط. بل نضعها داخل “بيئة” تفاعلية، ونمنحها حرية اتخاذ القرارات. كل قرار ينتج عنه نتيجة: إما مكافأة أو عقوبة. ومع مرور الوقت، تتعلم الآلة أن تختار الأفعال التي تزيد من مكاسبها وتقلل من خسائرها. تشبه هذه العملية تدريب كلب على أداء مهمة، حيث يتعلم من خلال المكافأة المتكررة ما هو السلوك الصحيح.
تعتمد خوارزميات التعلم بالتعزيز على مفهوم “المكافأة المؤجلة”، أي أن الآلة قد لا ترى نتيجة فعلها فورًا، لكنها تتعلم مع الوقت أن تربط القرارات الصحيحة بالنتائج الجيدة على المدى البعيد. هذا هو المبدأ الذي جعل خوارزمية AlphaGo من شركة DeepMind تهزم أبطال العالم في لعبة Go، حيث جرّبت ملايين الخطط والاحتمالات في بيئة افتراضية، لتتعلم وحدها متى تهاجم ومتى تتراجع.
ولا تقتصر تطبيقاته على الألعاب. يُستخدم التعلم بالتعزيز اليوم في:
• تدريب الروبوتات على المشي أو الإمساك بالأشياء بدقة في بيئات معقدة.
• تطوير أنظمة القيادة الذاتية التي تتعلم التعامل مع مواقف غير متوقعة على الطرق.
• تحسين أنظمة إدارة الطاقة التي توازن بين الكفاءة والاستهلاك في الوقت الفعلي.
• دعم الاستراتيجيات المالية في تحليل الأسواق واقتراح قرارات تداول ذكية.
• وحتى في الطب، لتخطيط العلاجات الدوائية أو تحسين مسارات الجرعات العلاجية بناءً على رد فعل المريض.
هذا النوع من التعلم يمنح الأنظمة قدرة مذهلة على اختبار آلاف السيناريوهات في ثوانٍ، واختيار الحل الأمثل ليس فقط من حيث الدقة، بل من حيث الكلفة والسرعة والموثوقية. في بيئة مليئة بالمتغيرات، يتصرّف النظام كما لو كان “يفكر” عبر التجربة، يتعلم من الأخطاء، ويبحث عن أفضل استراتيجية ممكنة.
ومع تطور الذكاء الاصطناعي، أصبحت الأنظمة قادرة على التعلم من بيانات ناقصة أو غير مكتملة. فالخوارزميات الحديثة تستطيع ربط أجزاء صغيرة من المعلومات ببعضها بعضًا ورسم صورة أوسع للمشهد. ما كان في الماضي “معلومة غير مهمة” يمكن اليوم أن يشكّل مفتاحًا لفهم النمط الكامل. هذا يعني أن البيانات التي نتركها هنا وهناك حتى وإن بدت عشوائية أو مموّهة يمكن أن تُستعاد وتُحلّل لتكشف اتجاهات وسلوكيات دقيقة عبر واحد من أنماط التعلم الثلاثة، سواء كانت مُراقبة أو غير مُراقبة أو بالتعزيز.
إننا نعيش في زمن تتقاطع فيه التجربة والخوارزمية، حيث لم يعد الذكاء الاصطناعي مجرد متلقٍّ للبيانات، بل كيان تعلّمي ديناميكي يتقن التعلّم من كل إشارة، مهما كانت صغيرة. وفي قلب هذا التحوّل يقف التعلم بالتعزيز، التقنية التي تعلّم الآلات كيف تفكر بالفعل: من خلال التجربة، والاختبار، والمكافأة.